在什么场景下会使用 ThreadLocal
场景一:ThreadLocal+MDC 实现链路日志增强
比如我们需要在整个链路的日志中输出当前登录的用户 ID,首先就得在拦截器获取过滤器中获取用户 ID,然后将用户 ID 进行存储到 ThreadLocal。
然后再层层进行透传,如果用的 Dubbo,那么就在 Dubbo 的 Filter 中进行传递到下一个服务中。问题来了,在 Dubbo 的 Filter 中如何获取前面存储的用户 ID 呢?
答案就是 ThreadLocal。获取后添加到 MDC 中,就可以在日志中输出用户 ID。
场景二:ThreadLocal 实现线程内的缓存,避免重复调用
场景三:ThreadLocal 实现数据库读写分离下强制读主库
首先你的项目中要做了读写分离,如果有对读写分离不了解的同学可以查看这篇文章:读写分离
某些业务场景下,必须保证数据的及时性。主从同步有延迟,可以使用强制读主库来保证数据的一致性。
在 Sharding JDBC 中,有提供对应的 API 来设置强制路由到主库,具体代码如下:
1 | HintManager hintManager = HintManager.getInstance(); |
HintManager 中就使用了 ThreadLocal 来存储相关信息。这样就可以实现在业务代码中设置路由信息,在底层的数据库路由那块获取信息,实现优雅的数据传递。
1 | public final class HintManager implements AutoCloseable { |
场景四:ThreadLocal 实现同一线程下多个类之间的数据传递
在 Spring Cloud Zuul 中,过滤器是必须要用的。用过滤器我们可以实现权限认证,日志记录,限流等功能。
过滤器有多个,而且是按顺序执行的。过滤器之前要透传数据该如何处理?
Zuul 中已经提供了 RequestContext 来实现数据传递,比如我们在进行拦截的时候会使用下面的代码告诉负责转发的过滤器不要进行转发操作。
1 | RequestContext.getCurrentContext().setSendZuulResponse(false); |
RibbonRoutingFilter 中就可以通过 RequestContext 获取对应的信息。
1 | @Override |
RequestContext 中就用了 ThreadLocal。
1 | public class RequestContext extends ConcurrentHashMap<String, Object> { |
其他场景
Spring 采用 Threadlocal 的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理 connection 对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
Spring 框架里面就是用的 ThreadLocal 来实现这种隔离,主要是在 **TransactionSynchronizationManager**这个类里面,代码如下所示:
1 | private static final Log logger = LogFactory.getLog(TransactionSynchronizationManager.class); |
Spring 的事务主要是 ThreadLocal 和 AOP 去做实现的,大家知道每个线程自己的链接是靠 ThreadLocal 保存的就好了,
除了源码里面使用到 ThreadLocal 的场景,你自己有使用他的场景么?一般你会怎么用呢?
使用场景1
之前我们上线后发现部分用户的日期居然不对了,排查下来是 SimpleDataFormat 的锅,当时我们使用 SimpleDataFormat 的 parse()方法,内部有一个 Calendar 对象,调用 SimpleDataFormat 的 parse()方法会先调用 Calendar.clear(),然后调用 Calendar.add(),如果一个线程先调用了 add()然后另一个线程又调用了 clear(),这时候 parse()方法解析的时间就不对了。
其实要解决这个问题很简单,让每个线程都 new 一个自己的 SimpleDataFormat 就好了,但是 1000 个线程难道 new1000 个 SimpleDataFormat?
所以当时我们使用了线程池加上 ThreadLocal 包装 SimpleDataFormat,再调用 initialValue 让每个线程有一个 SimpleDataFormat的副本,从而解决了线程安全的问题,也提高了性能。
使用场景2
我在项目中存在一个线程经常遇到横跨若干方法调用,需要传递的对象,也就是上下文(Context),它是一种状态,经常就是是用户身份、任务信息等,就会存在过渡传参的问题。
使用到类似责任链模式,给每个方法增加一个 context 参数非常麻烦,而且有些时候,如果调用链有无法修改源码的第三方库,对象参数就传不进去了。
所以我使用到了 ThreadLocal 去做了一下改造,这样只需要在调用前在 ThreadLocal 中设置参数,其他地方 get 一下就好了。
1 | before |
我看了一下很多场景的 cookie,session 等数据隔离都是通过 ThreadLocal 去做实现的。
使用场景3
在 Android 中,Looper 类就是利用了 ThreadLocal 的特性,保证每个线程只存在一个 Looper 对象。
1 | static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>(); |
ThreadLocal 的原理
1 | ThreadLocal<String> localName = new ThreadLocal(); |
其实使用真的很简单,线程进来之后初始化一个可以泛型的 ThreadLocal 对象,之后这个线程只要在 remove 之前去 get,都能拿到之前 set 的值,注意这里我说的是 remove 之前。他是能做到线程间数据隔离的,所以别的线程使用 get()方法是没办法拿到其他线程的值的,但是有办法可以做到
ThreadLocal 在使用的时候是单独创建对象的,更像一个全局的容器。但是大家有没有想过一个问题,就是为啥要设计 ThreadLocal 这个类,而不使用 HashMap 这样的容器类?
ThreadLocal 本质上是要解决线程之间数据的隔离,以达到互不影响的目的。如果我们用一个 Map 做数据存储,Key 为线程 ID, Value 为你要存储的内容,其实也是能达到隔离的效果。
没错,效果是能达到,但是性能就不一定好了,涉及到多个线程进行数据操作。如果你不看 ThreadLocal 的源码,你肯定也会以为 ThreadLocal 就是这么实现的。
ThreadLocal 在设计这块很巧妙,会在 Thread 类中嵌入一个 ThreadLocalMap,ThreadLocalMap 就是一个容器,用于存储数据的,但它在 Thread 类中,也就说存储的就是这个 Thread 类专享的数据。
原本我们以为的 ThreadLocal 设置值的代码:
1 | public void set(T value) { |
设置值的代码:
1 | public void set(T value) { |
可以看到,先是获取当前线程对象,然后从当前线程中获取线程的 ThreadLocalMap,值是添加到这个 ThreadLocalMap 中的,key 就是当前 ThreadLocal 的对象。从使用的 API 看上去像是把值存储在了 ThreadLocal 中,其实值是存储在线程内部,然后关联了对应的 ThreadLocal,这样通过 ThreadLocal.get 时就能获取到对应的值。
大家可以发现 set 的源码很简单,主要就是 ThreadLocalMap 我们需要关注一下,而 ThreadLocalMap 呢是当前线程 Thread 一个叫 threadLocals 的变量中获取的。
1 | ThreadLocalMap getMap(Thread t) { |
这里我们基本上可以找到 ThreadLocal 数据隔离的真相了,每个线程 Thread 都维护了自己的 threadLocals 变量,所以在每个线程创建 ThreadLocal 的时候,实际上数据是存在自己线程 Thread 的 threadLocals 变量里面的,别人没办法拿到,从而实现了隔离。
1 | public T get() { |
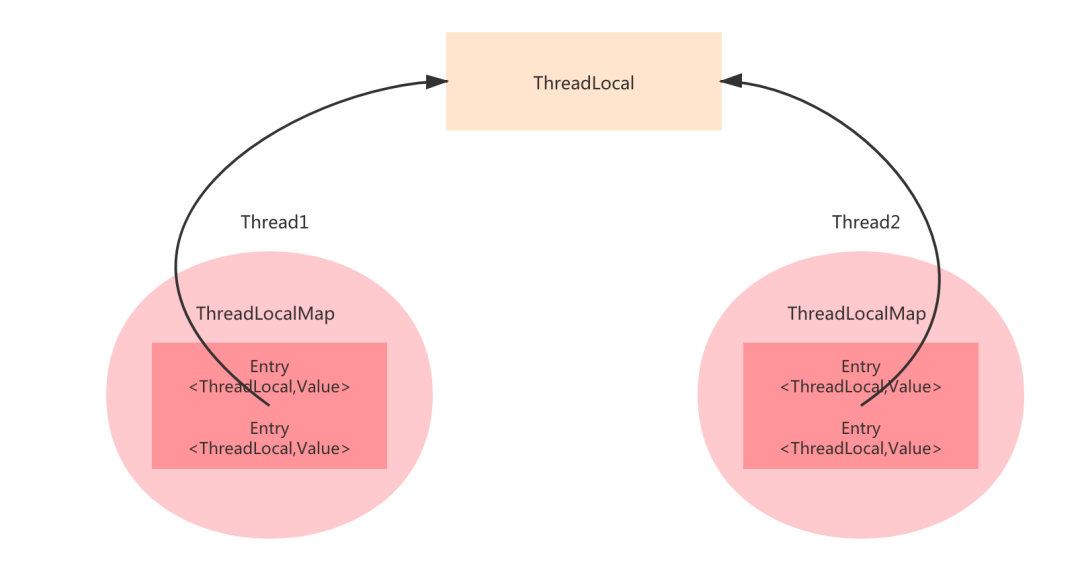
有个 Map 那他的数据结构其实是很像 HashMap 的,但是看源码可以发现,它并未实现 Map 接口,而且他的 Entry 是继承 WeakReference(弱引用)的,也没有看到 HashMap 中的 next,所以不存在链表了。
1 | static class ThreadLocalMap { |
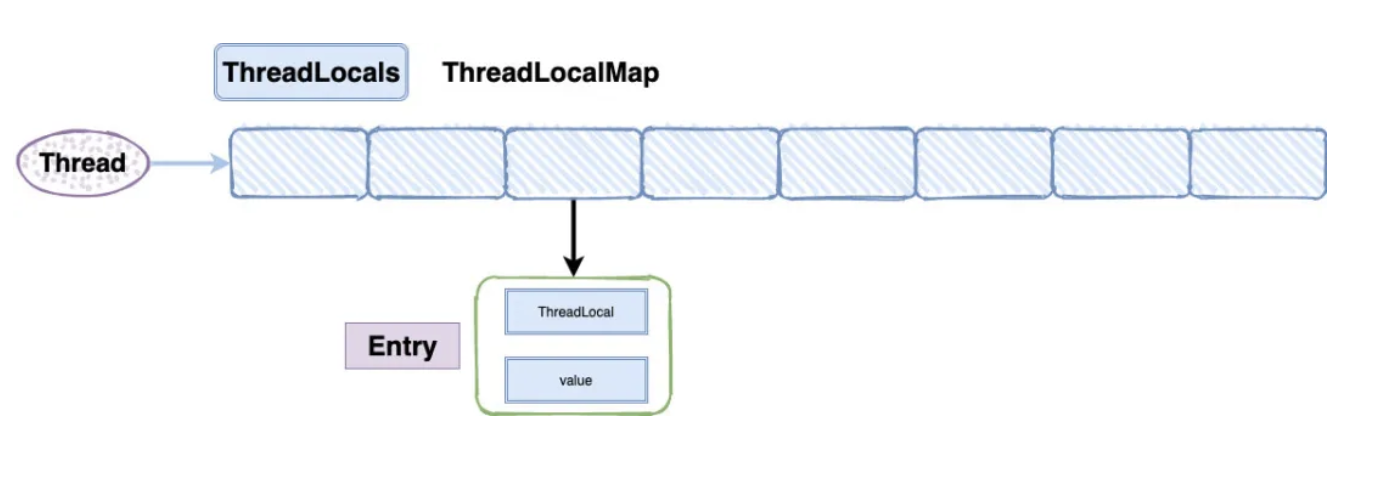
为什么需要数组呢?没有了链表怎么解决 Hash 冲突呢?
用数组是因为,我们开发过程中可以一个线程可以有多个 TreadLocal 来存放不同类型的对象的,但是他们都将放到你当前线程的 ThreadLocalMap 里,所以肯定要数组来存。
至于 Hash 冲突,我们先看一下源码:
1 | private void set(ThreadLocal<?> key, Object value) { |
我从源码里面看到 ThreadLocalMap 在存储的时候会给每一个 ThreadLocal 对象一个 threadLocalHashCode,在插入过程中,根据 ThreadLocal 对象的 hash 值,定位到 table 中的位置 i,int i = key.threadLocalHashCode & (len-1)。
然后会判断一下:
如果当前位置是空的,就初始化一个 Entry 对象放在位置 i 上;
1
2
3
4if (k == null) {
replaceStaleEntry(key, value, i);
return;
}如果位置 i 不为空,如果这个 Entry 对象的 key 正好是即将设置的 key,那么就刷新 Entry 中的 value;
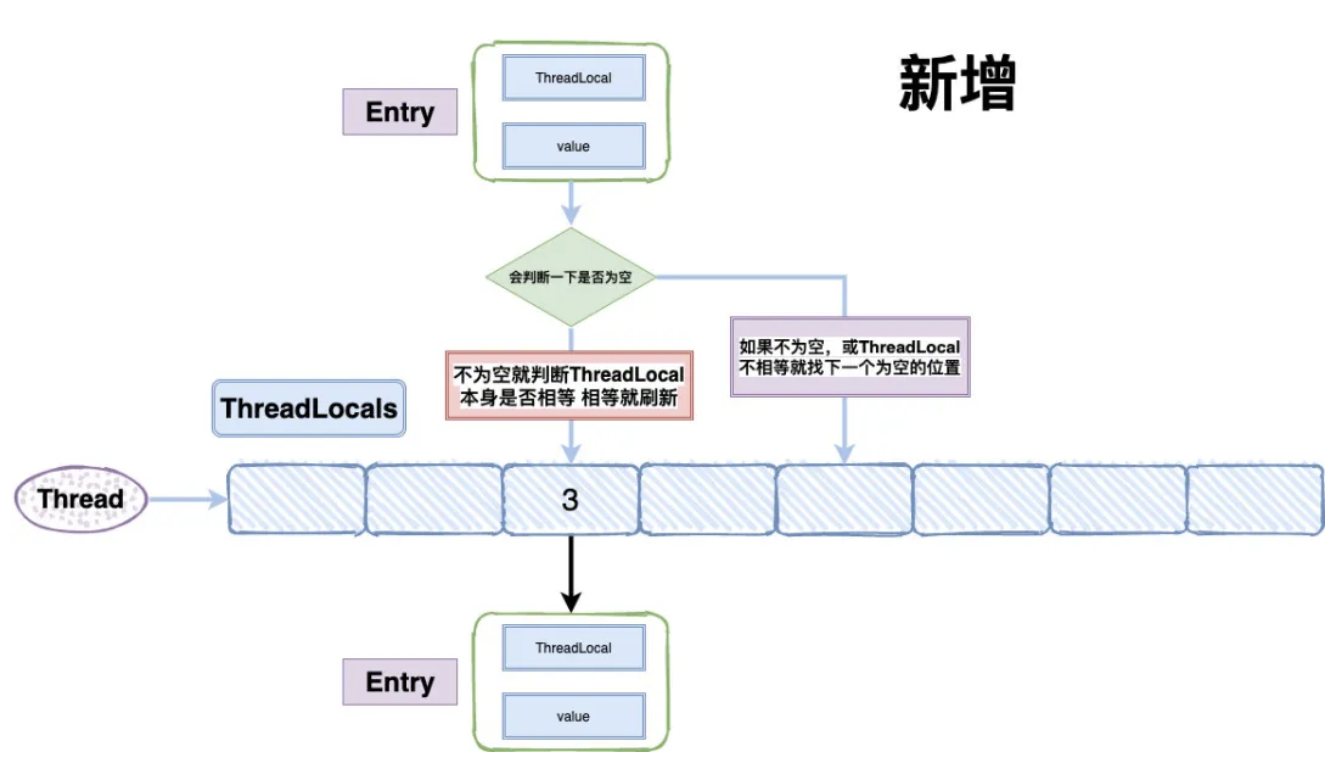
这样的话,在 get 的时候,也会根据 ThreadLocal 对象的 hash 值,定位到 table 中的位置,然后判断该位置 Entry 对象中的 key 是否和 get 的 key 一致,如果不一致,就判断下一个位置,set 和 get 如果冲突严重的话,效率还是很低的。
以下是 get 的源码,是不是就感觉很好懂了
1 | private Entry getEntry(ThreadLocal<?> key) { |
对象存放在哪里
在 Java 中,栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存,而堆内存中的对象对所有线程可见,堆内存中的对象可以被所有线程访问。
是不是说 ThreadLocal 的实例以及其值存放在栈上呢?
其实不是的,因为 ThreadLocal 实例实际上也是被其创建的类持有(更顶端应该是被线程持有),而 ThreadLocal 的值其实也是被线程实例持有,它们都是位于堆上,只是通过一些技巧将可见性修改成了线程可见。
如果我想共享线程的 ThreadLocal 数据怎么办?
使用 InheritableThreadLocal可以实现多个线程访问 ThreadLocal 的值,我们在主线程中创建一个 InheritableThreadLocal的实例,然后在子线程中得到这个 InheritableThreadLocal实例设置的值。
1 | private void test() { |
在子线程中我是能够正常输出那一行日志的,这也是我之前面试视频提到过的父子线程数据传递的问题。
怎么传递的呀
传递的逻辑很简单,我在开头 Thread 代码提到 threadLocals 的时候,你们再往下看看我刻意放了另外一个变量:
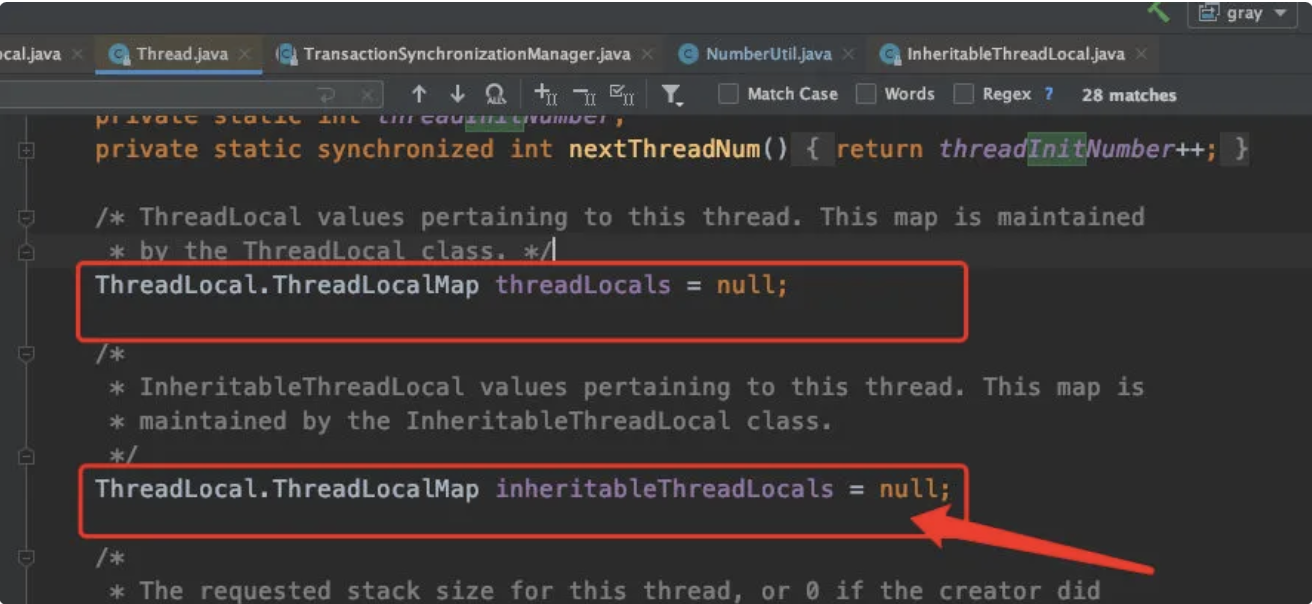
Thread 源码中,我们看看 Thread.init 初始化创建的时候做了什么:
1 | public class Thread implements Runnable { |
如果线程的 inheritThreadLocals变量不为空,比如我们上面的例子,而且父线程的 inheritThreadLocals也存在,那么我就把父线程的 inheritThreadLocals 给当前线程的 inheritThreadLocals。
内存泄露问题
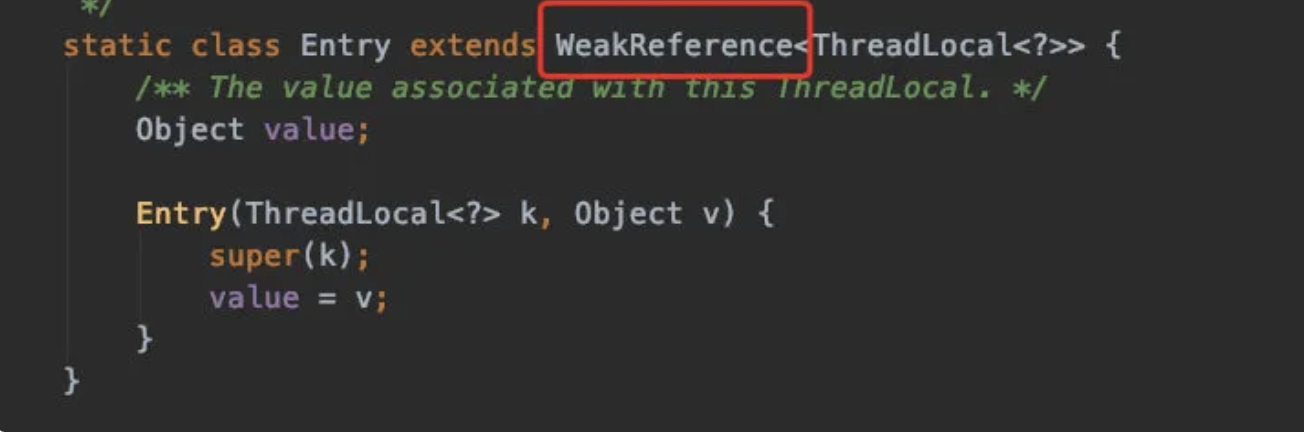
ThreadLocal 在保存的时候会把自己当做 Key 存在 ThreadLocalMap 中,正常情况应该是 key 和 value 都应该被外界强引用才对,但是现在 key 被设计成 WeakReference 弱引用了。
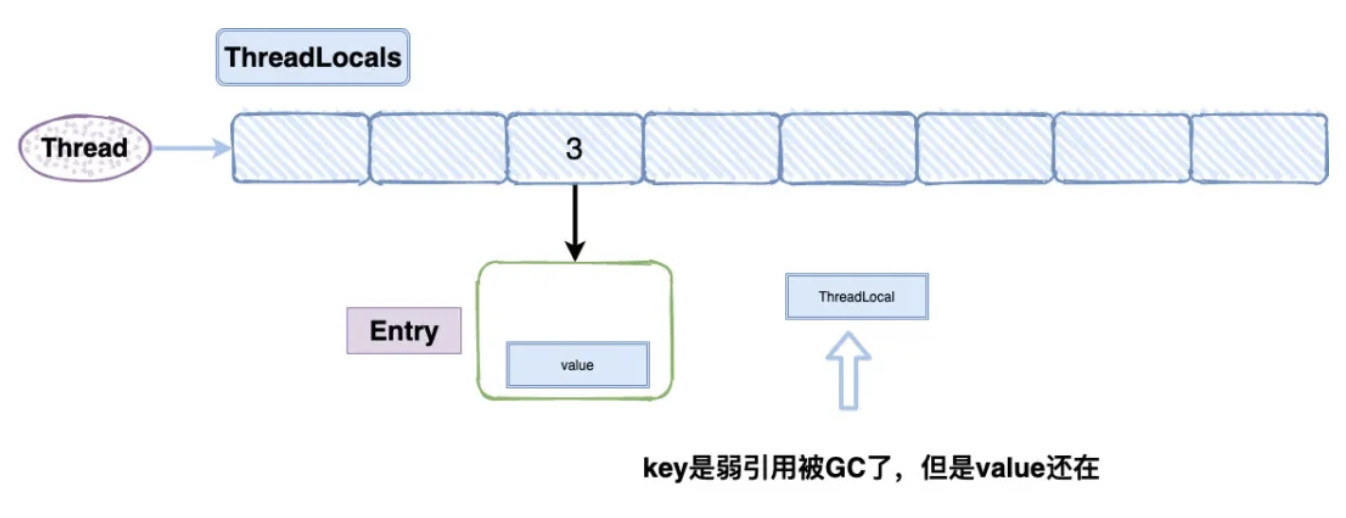
只具有弱引用的对象拥有更短暂的生命周期,在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
这就导致了一个问题,ThreadLocal 在没有外部强引用时,发生 GC 时会被回收,如果创建 ThreadLocal 的线程一直持续运行,那么这个 Entry 对象中的 value 就有可能一直得不到回收,发生内存泄露。
就比如线程池里面的线程,线程都是复用的,那么之前的线程实例处理完之后,出于复用的目的线程依然存活,所以,ThreadLocal 设定的 value 值被持有,导致内存泄露。
按照道理一个线程使用完,ThreadLocalMap 是应该要被清空的,但是现在线程被复用了。
怎么解决内存泄露
在代码的最后使用 remove 就好了,我们只要记得在使用的最后用 remove 把值清空就好了。
1 | ThreadLocal<String> localName = new ThreadLocal(); |
remove 的源码很简单,找到对应的值全部置空,这样在垃圾回收器回收的时候,会自动把他们回收掉。
那为什么 ThreadLocalMap 的 key 要设计成弱引用?
key 不设置成弱引用的话就会造成和 entry 中 value 一样内存泄漏的场景。
补充一点:ThreadLocal 的不足,我觉得可以通过看看 netty 的 fastThreadLocal 来弥补
使用 ThreadLocal 需要注意的地方
- 避免跨线程异步传递,虽然有解决方案,文末介绍了方案
- 使用时记得及时 remove, 防止内存泄露
- 注释说明使用场景,方便后人
- 对性能有极致要求可以参考开源框架的做法,用一些优化后的类,比如 FastThreadLocal
有什么方式能提高 ThreadLocal 的性能
因为在一些开源的框架中也有使用 ThreadLocal 的场景,但是这些框架为了让性能更好,一般都会做一些优化。
比如 Netty 中就重写了一个 FastThreadLocal 来代替 ThreadLocal,性能在一定场景下比 ThreadLocal 更好。
性能提升主要表现在如下几点:
- FastThreadLocal 操作数据的时候,会使用下标的方式在数组中进行查找来代替 ThreadLocal 通过哈希的方式进行查找。
- FastThreadLocal 利用字节填充来解决伪共享问题。
其实除了 Netty 中对 ThreadLocal 进行了优化,自定义了 FastThreadLocal。在其他的框架中也有类似的优化,比如 Dubbo 中就 InternalThreadLocal,根据源码中的注释,也是参考了 FastThreadLocal 的设计,基本上差不多。
如何将 ThreadLocal 的数据传递到子线程中
InheritableThreadLocal 可以将值从当前线程传递到子线程中,但这种场景其实用的不多,我相信很多人都没怎么听过 InheritableThreadLocal。
那为什么 InheritableThreadLocal 就可以呢?
InheritableThreadLocal 这个类继承了 ThreadLocal,重写了 3 个方法,在当前线程上创建一个新的线程实例 Thread 时,会把这些线程变量从当前线程传递给新的线程实例。
1 | public class InheritableThreadLocal<T> extends ThreadLocal<T> { |
通过上面的代码我们可以看到 InheritableThreadLocal 重写了 childValue, getMap,createMap 三个方法,当我们往里面 set 值的时候,值保存到了 inheritableThreadLocals 里面,而不是之前的 threadLocals。
关键的点来了,为什么当创建新的线程时,可以获取到上个线程里的 threadLocal 中的值呢?原因就是在新创建线程的时候,会把之前线程的 inheritableThreadLocals 赋值给新线程的 inheritableThreadLocals,通过这种方式实现了数据的传递。
源码最开始在 Thread 的 init 方法中,如下:
1 | if (parent.inheritableThreadLocals != null) |
createInheritedMap 如下:
1 | static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) { |
赋值代码:
1 | private ThreadLocalMap(ThreadLocalMap parentMap) { |
线程池中如何实现 ThreadLocal 的数据传递
如果涉及到线程池使用 ThreadLocal, 必然会出现问题。首先线程池的线程是复用的,其次,比如你从 Tomcat 的线程到自己的业务线程,也就是跨线程池了,线程也就不是之前的那个线程了,也就是说 ThreadLocal 就用不了,那么如何解决呢?
可以使用阿里的 ttl 来解决,之前我也写过一篇文章,可以查看:Spring Cloud 中 Hystrix 线程隔离导致 ThreadLocal 数据丢失
贴上 ttl 的链接:https://github.com/alibaba/transmittable-thread-local
