研发背景
在分布式服务中,各种复杂的业务场景需要有一个用于做唯一标识的id,例如订单业务,支付流水,聊天通信等业务场景。尤其是在分库分表场景中,分布式id生成器的使用频率更高。因此分布式id组件的设计应该要能支持以下几个特性:
1.全局唯一特性
这个点比较好理解,这里就不做过多的解释。
2.组件递增特性
可以是每个id都具有递增的特性也可以是支持区间段内具备递增的特性。
3.安全性
有些重要的id如果无意中暴露在了外网环境中,如果没有做过安全防范其实是一件非常危险的事情。例如说订单的id如果只是更具日期加订单数目的格式生成,例如说:2020111100001表示2020年11月11日的第一笔订单,那么如果竞对获取到了
2020111100999这个id,再根据订单的生成时间则大概可以推断出该公司某日生成的订单数目的大致量级。
4.高qps
分布式id生成组件在使用过程中主要是qps偏高,因此在设计起初应该要能支持较高的qps查询,同时对于网络的延迟特性也需要尽可能降低。
5.高可用
由于分布式id生成器是一个需要支持多个服务调用方共同使用的公共服务,一旦出现崩溃后果不堪设想,可能会导致大面积的业务线崩塌,所以在高可用方面需要考虑得尤其重要。
业界常见的分布式id生成方案比对
uuid
java程序中实现uuid的代码:
1 | String result = UUID.randomUUID().toString(); |
生成的格式如下所示:
1 | b0b2197d-bc8c-4fab-ad73-2b54e11b0869 |
uuid的格式其实是会被 - 符号划分为五个模块,主要是分为了8-4-4-4-12个字符拼接而成的一段字符串。但是这种字符串的格式对于互联网公司中主推的MySQL数据库并不友好。
尤其是当使用生成的id作为索引的时候,uuid长度过长,大数据量的时候会导致b+树的叶子结点裂变频率加大,而且在进行索引比对的时候需要进行逐个字符比对,性能损耗也较高,应该抛弃该方案。uuid的主要组成由以下几个部位:
- 当前日期和时间
- 随机数字
- 机器的MAC地址(能够保证全球范围内机器的唯一特性)
雪花算法
SnowFlake是Twitter公司采用的一种算法,目的是在分布式系统中产生全局唯一且趋势递增的ID。
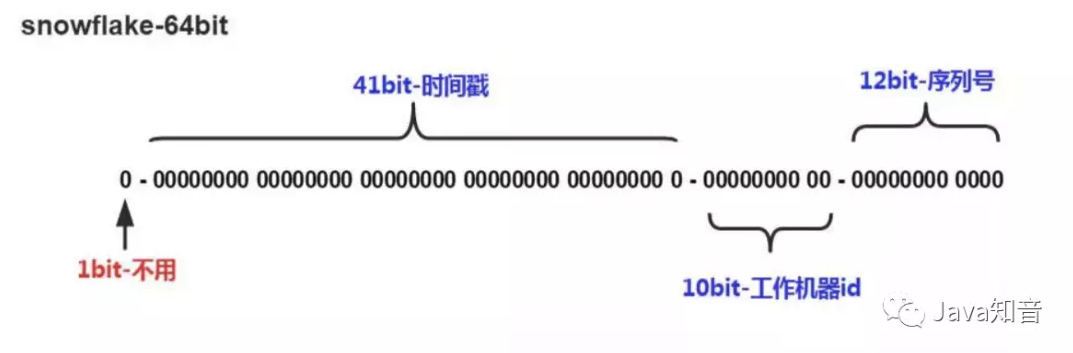
稍微解释一些雪花算法的含义:
第一位通常是0,没有特殊使用含义,因为1通常表示为补码。
中间的41位是用于存储时间,41位的长度足够容纳69年左右的时长。
10bit用于标示机器自身的id,从而表示不通机器自身id的不同。
最后12位bit用于表示某一毫秒内的序列号,12位(bit)可以表示的最大正整数是4096-1=4095,所以也就是说一毫秒内可以同时生成4095个id。
时间戳位置和序列号位置还不能随意调整,应为要保证逐渐递增的特性。
好处
能够保证递增的特性,id具有明确的含义,易懂。
不足点
但是对于机器自身的系统时间有所依赖,一旦机器的系统时间发生了变化,在高并发环境下就有可能会有重复id生成的风险。
有些业务场景希望在id中加入特殊的业务规则名称前缀
例如短信的id:
1 | sms_108678123 |
奖券的id:
1 | coupon_12908123 |
需要基于这种算法进行改造,实现支持id注入“基因”的这一特性。
mongodb的主键id设计思路
其实在mongodb里面也有使用到往主键id中注入一些“基因”要素点的这类思路:
mongodb里面没有自增的id。

_id是唯一标识的key,value通常我们会设置为objectid对象。
objectid里面包含了时间戳,宿主机的ip,进程号码,自增号

自研主要设计思路
MySQL配置id生成规则,拉取到本地缓存中形成一段本地id,从而降低对于db的访问。
支持集群配置id生成器,能够支持高qps访问和较好的扩容性。
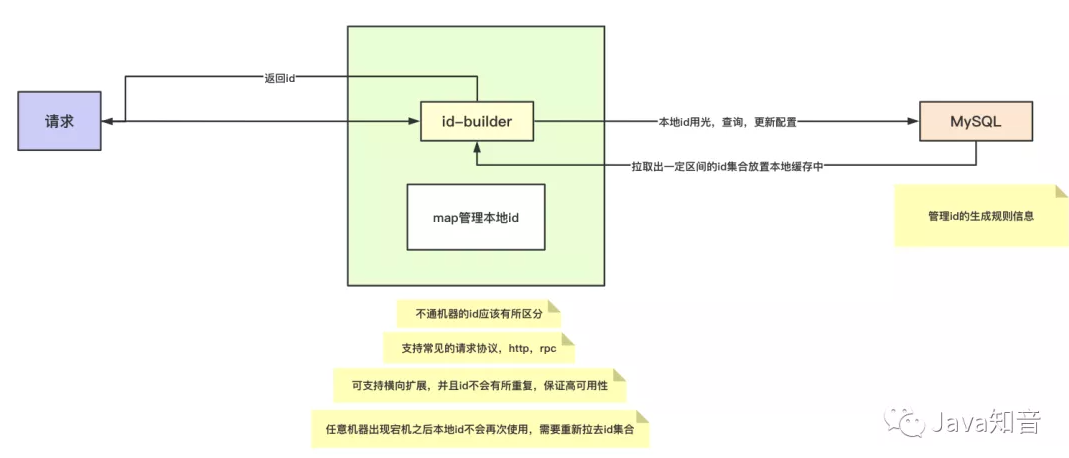
配置表如下方所示:

建表sql:
1 | CREATE TABLE `t_id_builder_config` ( |
几个核心设计点:
当同时有多个请求访问mysql获取id配置的时候该如何防止并发问题?
这里我采用了for update的方式加行锁进行读取,同时对于行信息进行更新的时候加入了version版本号信息字段防止更新重复的情况。
假设说更新失败,也会有cas的方式进行重试,重试超过一定次数之后直接中断。
为何不引入redis作为分布式锁来防止并发修改数据库操作?
不希望将该组件变得过于繁杂,减少系统对于第三方的依赖性
假设本地id还没使用完,结果当前服务器宕机了,该如何预防?
每次服务启动都需要更新表的配置,拉去最新的一批id集合到本地,这样就不会出现和之前id冲突的问题了。
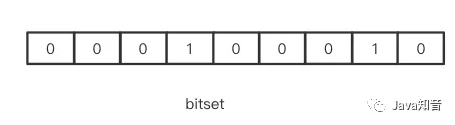
本地id集合中如何判断id是否已经使用过?
如果是连续递增型的id,这一步可以忽略,因为本地id每次获取的时候都会比上一个id要大。但是如果是拉取了一段区间的id到本地之后进行随机返回就需要加入bitset作为过滤器了。对于已经使用过的id,则对应bit置为1。如果随机返回的区间id多次都已经被占用了,则超过一定频率之后需要重新拉取id到本地。
不通机器的状态表示码该如何设置?
可以通过启动脚本中配置相关参数:
1 | -DidBuilder.index=1001 |
进行配置,然后通过System.getProperty(“idBuilder.index”)的方式来获取.
核心代码思路:
接口设计:
1 | public interface IdBuilderService { |
具体实现:
1 | public class IdBuilderServiceImpl implements IdBuilderService, InitializingBean { |
application.yml配置文件:
1 | mybatis-plus: |
注意需要结合实际机器配置nginx的并发线程数目和tomcat的并发访问参数。
测试环节:
通过将服务打包部署在机器上边,同时运行多个服务,通过nginx配置负载均衡,请求到不同的机器上边。
压测的一些相关配置参数:
当我们需要扩增机器的时候,新加的机器不会对原有发号令机器的id产生影响,可以支持较好的扩容。
每次拉取的本地id段应该设计在多次较好?
这里我们先将本地id段简称为segment。
按照一些过往经验的参考,通常是希望id发号器能够尽量减少对于MySQL的访问次数,同时也需要结合实际部门的运维能力进行把控。
假设说我们MySQL是采用了1主2从的方式搭建,当某一从节点挂了,切换新的从节点时候需要消耗大约1分钟时长,那么我们的segment至少需要设计为高峰期QPS * 60 * 1 * 4 ,期间考需要额外考虑一些其他因素,例如网络新的节点切换之后带来的一些网络抖动问题等等,这能够保证即使MySQL出现了故障,本地的segment也可以暂时支撑一段时间。
设计待完善点:
该系统的设计不足点在于,当本地id即将用光的时候需要进行数据库查询,因此这个关键点会拖慢系统的响应时长,所以这里可以采用异步更新配置拉取id的思路进行完善。也就是说当本地id列表剩余只有15%可以使用的时候,便可以进行开启一个异步线程去拉取id列表了。
